数据结构第四章作业
第一题
分别求出下列模式串的next和nextval数组值。
解:
t1 = 'aaab'- next : 0 1 2 3
- nextval: 0 0 0 3
t2 = 'abcabaa'- next: 0 1 1 1 2 3 2
- nextval: 0 1 1 0 1 3 2
t3 = 'adabbadada'- next: 0 1 1 2 1 1 2 3 2 3
- nextval: 0 1 0 2 1 0 1 0 4 0
第二题
重复子串的含义是由一个或多个连续相等的字符组成的子串(不重叠);现有某个串用一维字符数组s存储,长度为n,设计算法求s的最长重复子串的长度。
解法一:
朴素的暴力做法是非常显然的,输入字符串的每一个子串都有可能成为重复子串,我们只需枚举重复子串,再使用KMP进行模式匹配,最后检查不重叠位置的匹配数量是否大于1,取满足条件的最长子串长度即可。时间复杂度 \(O(n^3)\)。
int LongestString(char s[], int n) {
int ans = 0;
for (int l = 0; l < n; l++) {
for (int r = l + 1; r <= n; r++) {
// 枚举子串s[l,r), 进行模式匹配
int len = r - l;
int* next = (int*) calloc(len, sizeof(int));
next[0] = 0;
for (int i = 1, j = 0; i < len; i++) {
while (j > 0 && s[l+i] != s[l+j]) j = next[j-1];
if (s[l+i] == s[l+j]) ++j;
next[i] = j;
}
// 统计匹配个数
int match = 0;
for (int i = 0, j = 0; i < n; i++) {
while (j > 0 && s[i] != s[l+j]) j = next[j-1];
if (s[i] == s[l+j]) ++j;
if (j == len) {
// 不重叠匹配
j = 0;
match++;
}
}
if (match > 1 && len > ans) {
ans = len;
}
free(next);
}
}
return ans;
}
解法二:
注意到重复子串的长度具有单调性,即如果 \(L\) 是最长重复子串长度,那么对于所有 \(x \le L\),都存在长度为 \(x\) 的重复子串。基于这一性质,我们可以对子串长度进行二分,每次枚举固定长度的子串,然后使用KMP模式匹配来进行验证。时间复杂度 \(O(n^2log{n})\)。
int LongestString(char s[], int n) {
int L = 0, R = n / 2, ans = 0;
while (L <= R) {
// 二分长度
int len = (L + R) / 2;
bool ok = false;
for (int p = 0; p + len <= n && !ok; p++) {
// 模式匹配
int* next = (int*)calloc(len, sizeof(int));
for (int i = 1, j = 0; i < len; i++) {
while (j > 0 && s[p + i] != s[p + j]) j = next[j - 1];
if (s[p + i] == s[p + j]) ++j;
next[i] = j;
}
int match = 0;
for (int i = 0, j = 0; i < n; i++) {
while (j > 0 && s[p + i] != s[p + j]) j = next[j - 1];
if (s[i] == s[p + j]) ++j;
if (j == len) {
match++;
j = 0;
}
}
if (match >= 2) {
ok = true;
}
}
if (ok) {
ans = len;
L = len + 1;
} else {
R = len - 1;
}
}
return ans;
}
解法三:
以上两个解法的时间复杂度瓶颈都在于枚举子串。事实上,我们所需要的子串只是很少的一部分,想要进一步优化,关键在于找到一个高效地枚举子串的方法。注意到一个字符串的子串必然是这个字符串某一后缀的前缀,有以下解法:
-
将字符串s的所有后缀按照字典序进行排序。
-
求出排序后相邻后缀的最长公共前缀。(我们要求的重复子串必然出现在公共前缀中)
-
对于每个最长公共前缀,通过其在后缀中的位置判断是否重叠,对于不重叠的,更新答案
这里我们需要用到后缀数组,下面详细阐述:
定义 \(sa_i\) 为将所有后缀按照字典序排序后第 \(i\) 小的后缀编号,也就是后缀数组;定义 \(rk_i\) 表示后缀 \(i\) 的排名。字符串下标从 \(1\) 开始。
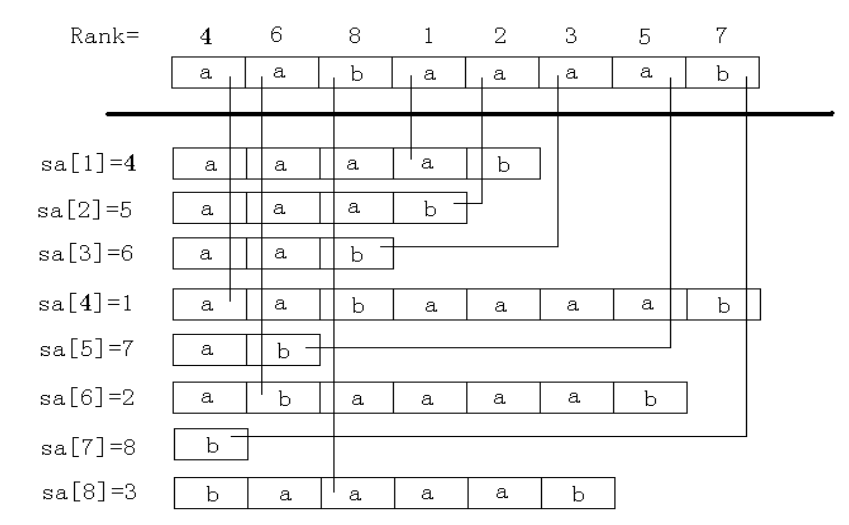
第一步,我们需要预处理 \(sa\)和 \(rk\) 两个数组,高效地预处理需要运用倍增:
倍增过程:
-
用两个长度为 \(1\) 的子串的排名,即 \(rk_1[i]\) 和 \(rk_1[i+1]\),作为排序的第一第二关键字,就可以对字符串 \(s\) 的每个长度为 \(2\) 的子串:\(\{s[i\dots \min(i+1, n)]\ |\ i \in [1,\ n]\}\) 进行排序,得到 \(sa_2\) 和 \(rk_2\);
-
之后用两个长度为 \(2\) 的子串的排名,即 \(rk_2[i]\) 和 \(rk_2[i+2]\),作为排序的第一第二关键字,就可以对字符串 \(s\) 的每个长度为 \(4\) 的子串:\(\{s[i\dots \min(i+3, n)]\ |\ i \in [1,\ n]\}\) 进行排序,得到 \(sa_4\) 和 \(rk_4\);
-
以此倍增,用长度为 \(w/2\) 的子串的排名,即 \(rk_{w/2}[i]\) 和 \(rk_{w/2}[i+w/2]\),作为排序的第一第二关键字,就可以对字符串 \(s\) 的每个长度为 \(w\) 的子串 \(s[i\dots \min(i+w-1,\ n)]\) 进行排序,得到 \(sa_w\) 和 \(rk_w\)。其中,类似字母序排序规则,当 \(i+w>n\) 时,\(rk_w[i+w]\) 视为无穷小;
-
\(rk_w[i]\) 即是子串 \(s[i\dots i + w - 1]\) 的排名,这样当 \(w \geqslant n\) 时,得到的编号数组 \(sa_w\),也就是我们需要的后缀数组。
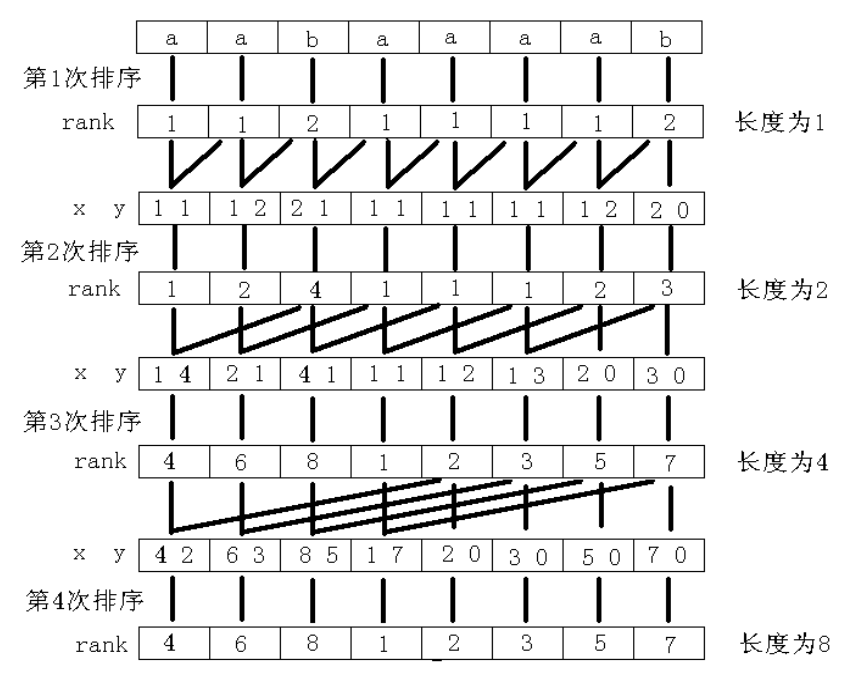
倍增的过程是 \(O(\log n)\),每次倍增使用基数排序 \(O(n)\),每次子串的比较花费 \(2\) 次字符比较,因此预处理的复杂度是 \(O(n\log{n})\)。
第二步,我们需要求出字典序相邻后缀的最长公共前缀。
定义 \(lcp(i, j)\) 为后缀 \(i\) 和 \(j\) 的最长公共前缀长度,定义 \(height_i = \begin{cases} \operatorname{lcp}(sa_i, sa_{i-1}), & i > 1 \\ 0, & i = 1 \end{cases}\)。
我们有引理: $$ height[rk[i]]\ge height[rk[i-1]]-1 $$ 这是由后缀字典序排序的结果,证明略。
从而我们可以高效地求出 \(height\) 数组:
for (i = 1, k = 0; i <= n; ++i) {
if (rk[i] == 0) continue;
if (k) --k;
while (s[i + k] == s[sa[rk[i] - 1] + k]) ++k;
height[rk[i]] = k;
}
k最多减n次,最多加2n次,时间复杂度为 \(O(n)\)。
第三步,我们遍历 \(height\) 数组,如果 \(sa_i-sa_{i-1}\ge height_i\) 说明 \(height_i\) 是一个合法的不重叠重复子串长度。取最大值就得到了我们最终要求的答案。时间复杂度 \(O(n)\)。
综上,我们总的时间复杂度 \(T(n)=O(n\log n) + O(n) + O(n) = O(n \log n)\)。
如果采用DC3算法进行后缀数组的预处理,还可以优化到 \(O(n)\)。但是常数较大,实现较复杂,这里不再深入讨论。
全部实现代码:
// 函数功能:构造后缀数组
// 参数:
// s : 输入字符串,要求从下标 1 开始存放,s[1..n]
// n : 字符串长度
// sa : 存放构造出的后缀数组,sa[1..n];sa[i] 表示第 i 小的后缀的起始位置
// rk : 排名数组,rk[1..(n<<1)],保存每个位置的排名
// oldrk : 辅助数组,与 rk 大小相同,存放上一轮的排名
// id : 辅助数组,用于计数排序过程中存放下标(大小 >= n+1)
// cnt : 计数数组,大小至少应能容纳各个可能取值的排名(一般 ≥ n+1 或更大)
void build_sa(const char s[], int n, int sa[], int rk[], int oldrk[], int id[], int cnt[]) {
int i, m, p, w;
// 初始 m 取字符集的最大 ASCII 值,这里假设 s 中字符 ASCII 范围在 [1,127]
m = 127;
// 统计字符频率,并初始化 rk 数组
// 注意 s 从下标 1 开始,故 i 从 1 到 n
for (i = 1; i <= n; ++i) {
rk[i] = s[i]; // 初始化排名为对应字符的 ASCII 值
cnt[ rk[i] ]++; // 统计频数
}
// 累加计数数组
for (i = 1; i <= m; ++i)
cnt[i] += cnt[i - 1];
// 利用计数排序构造初始 sa 数组
for (i = n; i >= 1; --i)
sa[ cnt[rk[i]]-- ] = i;
// 将初始排名复制到 oldrk 数组
memcpy(oldrk + 1, rk + 1, n * sizeof(int));
// 更新 rk 数组:对于 sa 中相邻下标相同则保持相同排名,否则排名加 1
for (p = 0, i = 1; i <= n; ++i) {
if (i > 1 && oldrk[ sa[i] ] == oldrk[ sa[i - 1] ])
rk[ sa[i] ] = p;
else
rk[ sa[i] ] = ++p;
}
// 主循环: w 表示比较的长度,初始 w = 1,每轮 w 翻倍,直到 w >= n
for (w = 1; w < n; w <<= 1, m = n) {
// 对第二关键字:对于下标 i 的第二关键字为 rk[i + w]
// 先将当前 sa 复制到辅助数组 id
memcpy(id + 1, sa + 1, n * sizeof(int));
// 计数数组清零
memset(cnt, 0, (m + 1) * sizeof(int));
// 根据第二关键字统计频数,注意:若 i+w 超出范围,则 rk[i+w] 默认为 0
for (i = 1; i <= n; ++i)
cnt[ rk[id[i] + w] ]++;
// 累加计数
for (i = 1; i <= m; ++i)
cnt[i] += cnt[i - 1];
// 根据第二关键字逆序排序,更新 sa 数组
for (i = n; i >= 1; --i)
sa[ cnt[ rk[id[i] + w] ]-- ] = id[i];
// 对第一关键字:即 rk[ i ],同样采用计数排序
memcpy(id + 1, sa + 1, n * sizeof(int));
memset(cnt, 0, (m + 1) * sizeof(int));
for (i = 1; i <= n; ++i)
cnt[ rk[id[i] ] ]++;
for (i = 1; i <= m; ++i)
cnt[i] += cnt[i - 1];
for (i = n; i >= 1; --i)
sa[ cnt[ rk[id[i] ] ]-- ] = id[i];
// 保存上一轮的排名
memcpy(oldrk + 1, rk + 1, n * sizeof(int));
// 更新排名 rk 数组,根据 (rk[i], rk[i+w]) 生成新的排名
for (p = 0, i = 1; i <= n; ++i) {
if (i > 1 && oldrk[sa[i]] == oldrk[sa[i - 1]] &&
oldrk[sa[i] + w] == oldrk[sa[i - 1] + w])
rk[ sa[i] ] = p;
else
rk[ sa[i] ] = ++p;
}
}
}
// 函数功能:构造 height 数组
// 参数:
// s : 输入字符串,要求从下标 1 开始存放,s[1..n]
// n : 字符串长度
// sa : 后缀数组,sa[1..n];注意 sa 和 rk 数组均采用 1-based 索引
// rk : 排名数组,rk[1..n],其中 rk[i] 表示 s[i...] 在后缀数组中的位置
// height: 构造后的 height 数组,height[1..n],height[i] 表示 sa[i] 和 sa[i-1] 的最长公共前缀长度
void build_height(const char s[], int n, int sa[], int rk[], int height[]) {
int i, k;
// i 从 1 到 n, k 表示当前已经匹配的前缀长度
for (i = 1, k = 0; i <= n; ++i) {
// 如果当前后缀在 sa 中排第一,则没有前驱,不计算
if (rk[i] == 0)
continue;
// 若 k > 0,则递减 k(利用相邻后缀间的性质)
if (k) k--;
// j 为当前后缀在 sa 中前一个后缀的起始位置
int j = sa[rk[i] - 1];
// 比较 s[i+k] 与 s[j+k] 直到不等,注意 s 数组从 1 开始
while (i + k <= n && j + k <= n && s[i + k] == s[j + k])
k++;
height[ rk[i] ] = k;
}
}
const int N = 10000;
int LongestString(char s[], int n) {
// 下标从s[1]开始
int* sa = (int*) calloc(N , sizeof(int));
int* rk = (int*) calloc(N , sizeof(int));
int* oldrk = (int*) calloc(N , sizeof(int));
int* id = (int*) calloc(N , sizeof(int));
int* cnt = (int*) calloc(300 , sizeof(int));
int* height = (int*) calloc(N , sizeof(int));
build_sa(s, n, sa, rk, oldrk, id, cnt);
build_height(s, n, sa, rk, height);
int ans = 0;
for (int i = 2; i <= n; i++) {
if (height[i] > ans && abs(sa[i] - sa[i-1]) >= height[i]) {
ans = height[i];
}
}
free(sa), free(rk), free(oldrk), free(cnt), free(id), free(height);
return ans;
}