题目: Huffman编码
1. 需求分析
任务描述: 将任意一个指定的文件进行哈夫曼编码,并以真正的二进制位生成一个二进制文件(压缩文件);反过来,可将一个压缩文件解码还原为原来的文件。
输入/输出要求:
-
输入形式:运行参数,待压缩/解压文件地址,压缩/解压文件地址。
-
输出形式:压缩后的.huf文件。
功能要求:
- 对选定文件以二进制方式读入,一次读入1024字节。
- 正确构建Huffman树并基于此进行压缩和解压。
2. 概要设计
解决思路:
- 循环读入文件,统计字符频率。
- 根据频率构建Huffman树。
-
根据Huffman树得到编码表。
-
压缩时:
-
将频率表写入文件头部。
-
将编码后的字符按顺序写入文件。
-
解压时:
-
根据频率表建立Huffman树。
- 将Huffman树视作字典树,沿着字典树进行解码。
数据结构:
结构体绑定字符和频率。
typedef struct {
unsigned char ch;
ll cnt;
} Info;
二叉链表存储Huffman树。
typedef struct BiTNode {
Info data;
struct BiTNode *lc, *rc;
} BiTNode, *BiTree;
二叉堆加速Huffman树的构建。
typedef struct Heap {
BiTree heap[MAXN];
int size; // 堆中元素个数,存储在 heap[1..size] 中
} *PriorityQueue;
模块关系:
- 优先队列 / 小根堆:
init、_up、_down、push、pop,为每次合并取出最小频次节点提供支持。 - Huffman 树构建:
buildHuffmanTree(创建所有叶子并两两合并)、freeHuffmanTree(释放整棵树)。 - 编码表生成:
encode根据树从根到叶子记录路径 0/1 保存到table[ch]。 - 按位写入:
BitWriter的bw_init、bw_write_bit、bw_write_code、bw_flush,把一串'0'/'1'字符写成真正的比特流。 - 按位读取:
BitReader的br_init、br_read_bit,把文件读字节后拆分成一个一个比特。 - 压缩主逻辑:
compress_file,从频次统计到树构造、编码表、写头、按位写正文。 - 解压主逻辑:
decompress_file,从读头到重建树、按位读正文并沿树还原字节。 - 程序入口:
main负责解析命令行参数,决定调用“压缩”还是“解压”,并设置控制台编码。
3. 详细设计
关键算法:
-
void swap(BiTree *x, BiTree *y) -
作用:交换两个
BiTree指针(二叉树节点)的内容。 -
细节:在小根堆的上下调整过程中,用来交换堆数组里相邻元素的指针。
-
小根堆(PriorityQueue)相关函数 这组函数共同构成了一个基于数组的最小堆,用来每次取出当前频率最小的 Huffman 节点。
-
void init(PriorityQueue pq)- 作用:初始化一个空的优先队列(小根堆),把
size设为 0。
- 作用:初始化一个空的优先队列(小根堆),把
void _up(PriorityQueue pq, int i)- 作用:向上调整索引为
i的堆元素。 - 细节:如果
heap[i]的cnt(频次) 比其父节点更小,就一直交换直到堆性质恢复。
- 作用:向上调整索引为
void _down(PriorityQueue pq, int i)- 作用:向下调整索引为
i的堆元素。 - 细节:不断比较当前节点与它左右子节点的
cnt,把最小的浮到上面,直到 “父 ≤ 子” 满足小根堆条件。
- 作用:向下调整索引为
void push(PriorityQueue pq, BiTree x)- 作用:把一个新的 Huffman 子树
x插入堆中。 - 流程:先把
x放到堆尾 (heap[++size] = x),再调用_up保持堆序。
- 作用:把一个新的 Huffman 子树
-
BiTree pop(PriorityQueue pq)- 作用:从堆顶弹出当前最小频次的子树节点。
- 流程:取出
heap[1](最小),把堆尾元素移到heap[1],size--,然后调用_down恢复小根堆。返回原来的堆顶指针。
-
BiTree buildHuffmanTree(Info *arr, int n) -
作用:根据传入的
Info数组(包含ch和cnt)构造一棵 Huffman 树,并返回树根指针。 -
详细步骤:
- 若
n == 0返回NULL。 - 用
malloc分配一个PriorityQueue,调用init初始化。 - 遍历
arr[0..n-1],为每个Info新建一个BiTNode(叶子),把data.ch = arr[i].ch、data.cnt = arr[i].cnt,lc=rc=NULL,然后push入堆。 - 当堆中元素数
>1时:pop出两棵最小频次子树min、subMin;- 新建一个父节点
parent,令parent->data.cnt = min->cnt + subMin->cnt、parent->data.ch = 0(无实际字符),parent->lc = min、parent->rc = subMin; push(pq, parent),把它放回堆。
- 最终
pop(pq)就是 Huffman 树的根。释放堆本身的内存后返回根指针。
- 若
-
void freeHuffmanTree(BiTree root) -
作用:递归释放整棵 Huffman 树所占用的内存。
-
流程:先递归释放左子树和右子树,再
free(root)本节点。 -
void encode(BiTree root, char sign[], int p) -
作用:根据已构造好的 Huffman 树
root,生成从根到每个叶子节点(每个字符)的比特串编码,并把它保存到全局table[ch]中。 - 参数含义:
root:当前子树的根节点。sign[]:用来累积路径上写入的'0'或'1'。p:当前累积到sign[p-1]的长度。
-
实现细节:
- 如果
root == NULL直接返回。 - 若当前节点同时
lc == NULL && rc == NULL,说明这是叶子:- 若
p == 0(仅有一个符号),则强制给它编码"0"; - 否则把已经累积在
sign中的比特串复制到table[root->data.ch]。
- 若
- 如果有左子节点,就把
sign[p] = '0'、sign[p+1] = '\0',递归encode(root->lc, sign, p+1); - 如果有右子节点,就把
sign[p] = '1'、sign[p+1] = '\0',递归encode(root->rc, sign, p+1)。
- 如果
-
BitWriter 系列函数(按位写入) 用于把“字符对应的比特串”真正“打包到字节流”中。
-
void bw_init(BitWriter *bw, FILE *fp)- 作用:初始化一个
BitWriter,把fp赋给bw->fp,buffer=0,bitcount=0。
- 作用:初始化一个
void bw_write_bit(BitWriter *bw, int bit)- 作用:向
BitWriter中写入一个比特(0或1)。 - 流程:
bw->buffer <<= 1;左移一位,把当前 buffer 的高位空出来;if (bit) bw->buffer |= 1;如果要写入1,就把最低位设为 1。bw->bitcount++;如果bitcount == 8,说明buffer已填满 8 个比特,就fputc(buffer)写成一个字节到fp,然后buffer=0; bitcount=0;。
- 作用:向
void bw_write_code(BitWriter *bw, const char *code)- 作用:把一个以
'0'/'1'组成的 ASCII 字符串code(比如"01011")中的每个字符,依次调用bw_write_bit输出比特。
- 作用:把一个以
-
void bw_flush(BitWriter *bw)- 作用:在写入完成后,把
buffer中尚未凑满 8 位的那部分“左移补 0”并写出一个字节。 - 细节:如果
bitcount > 0,则buffer <<= (8 - bitcount),使低位补 0,把这个字节fputc输出,然后buffer=0,bitcount=0。
- 作用:在写入完成后,把
-
BitReader 系列函数(按位读取) 用于解压时把压缩文件的比特流拆分回一位一位,供 Huffman 树遍历使用。
-
void br_init(BitReader *br, FILE *fp)- 作用:初始化一个
BitReader,把fp赋给br->fp,buffer = 0,bitcount = 0。
- 作用:初始化一个
-
int br_read_bit(BitReader *br)- 作用:从
BitReader中读取一个比特(返回0或1),如果已到文件末尾且无更多数据,则返回-1。 - 流程:
- 如果
bitcount == 0,说明当前buffer里没有可读的比特,就fgetc(fp)再读一个字节到buffer,并把bitcount = 8; - 从
buffer的最高位取出 1 位:int bit = (buffer & 0x80) ? 1 : 0;,再把buffer <<= 1; bitcount--;;返回bit。
- 作用:从
-
void compress_file(const char *infile, const char *outfile) -
作用:把原文件
infile按照 Huffman 编码压缩,输出到outfile。 -
主要步骤:
- 统计频次:打开
infile,逐块读取到unsigned char buffer[1024]中,累加cnt[buffer[i]]++。 - 把
cnt[i] > 0的字节封装到Info signs[]中,计算出一共有tot种字符。 - 构建 Huffman 树:调用
buildHuffmanTree(signs, tot)获得HuffmanTree。 - 生成编码表:清空全局
table,再做一次encode(HuffmanTree, sign, 0),让table[ch]得到从根到该叶子的比特串(形如"01011")。 - 计算总比特数 & padding:遍历
i=0..255,if (cnt[i]>0) total_bits += cnt[i] * strlen(table[i]);然后padding = (8 - (total_bits % 8)) % 8。 - 写压缩头:打开
outfile(fopen(..., "wb")),先for (i=0..255) fwrite(&cnt[i], sizeof(ll), 1, fout),再fwrite(&padding, 1, 1, fout)。此时头部固定占用256×8 + 1 = 2049字节。 - 按位写正文:用
BitWriter bw; bw_init(&bw, fout);,回到infile头,每次fgetc(fin)得到ch,调用bw_write_code(&bw, table[ch]),最后调用bw_flush(&bw)把末尾不满 8 位的剩余比特写出。 - 关闭文件,释放
HuffmanTree、signs[],并在屏幕打印“压缩完成”的信息。
- 统计频次:打开
-
void decompress_file(const char *infile, const char *outfile) -
作用:把压缩文件
infile解压回原始内容,输出到outfile。 -
主要步骤:
- 读取压缩头:打开
infile("rb"),先for (i=0..255) fread(&cnt[i], sizeof(ll), 1, fin)读回频率表;再fread(&padding, 1, 1, fin)读回padding。 - 计算原始字节总数:
sum_cnt = sum(cnt[i] for i=0..255)。 - 重建 Huffman 树:与压缩时一致,把
cnt[i]>0的字节封装到signs[]中,调用buildHuffmanTree(signs, tot)得到HuffmanTree;(可选)再用encode(...)重新生成table,但真正解码时并不需要table,只要用树本身遍历即可。 - 按位读正文并还原:打开
outfile("wb"),初始化BitReader br; br_init(&br, fin);,令BiTree node = HuffmanTree; written = 0;- 循环
while (written < sum_cnt): bit = br_read_bit(&br),如果bit == -1报错结束;node = (bit == 0 ? node->lc : node->rc);- 如果
node是叶子(即node->lc==NULL && node->rc==NULL),令fputc(node->data.ch, fout); written++; node = HuffmanTree; - 循环直到写出
sum_cnt个字节。
- 循环
- 关闭文件,释放
HuffmanTree、signs[],并打印 “解压完成” 信息。
- 读取压缩头:打开
-
void print_usage(const char *progname)-
作用:当命令行参数不符合预期时,在标准错误上打印程序用法提示。
-
内容:
用法: 压缩:progname -c 原始文件路径 压缩后文件路径 解压:progname -d 压缩文件路径 解压后文件路径 -
-
int main(int argc, char *argv[])- 作用:程序入口,根据命令行参数决定“压缩”还是“解压”,或打印用法。
- 主要流程:
- 调用
SetConsoleOutputCP(CP_UTF8); SetConsoleCP(CP_UTF8);,使 Windows 控制台以 UTF-8 模式进行输入/输出,以保证中文提示正常显示。 - 检查
argc != 4,如果不等于 4,就调用print_usage(argv[0])并返回1。 - 如果
strcmp(argv[1], "-c") == 0,就调用compress_file(argv[2], argv[3]); 如果strcmp(argv[1], "-d") == 0,就调用decompress_file(argv[2], argv[3]);否则再次打印用法并返回1。 - 最后返回
0。
流程图:
- 小根堆
flowchart TD
A["开始"] --> B["初始化一个空堆,size = 0"]
B --> C{"执行操作类型?"}
C -->|"插入(push)"| D["将新节点放到堆尾"]
D --> E["向上调整:如果当前节点频次小于父节点,交换并继续向上"]
E --> F["完成插入操作,返回"]
C -->|"弹出(pop)"| G{"堆是否为空?"}
G -->|"是"| H["返回空 或 报错"]
G -->|"否"| I["取出堆顶(最小频次)"]
I --> J["将堆尾元素移到堆顶,size--"]
J --> K["向下调整:与子节点比较,选小者交换并继续向下"]
K --> L["返回原堆顶节点"]
- 构建 Huffman 树
flowchart TD
A["开始构建 Huffman 树"] --> B["准备一个小根堆"]
B --> C["把所有出现过的字符(叶子节点)按频次插入堆中"]
C --> D{"堆中元素>1?"}
D -->|"是"| E["弹出两个最小频次子树 A、B"]
E --> F["创建一个新内部节点 P,频次 = A与B的频次之和,左子树指向 A,右子树指向 B"]
F --> G["将新节点 P 插入堆"]
G --> D
D -->|"否"| H["堆中只剩一个节点,将其作为 Huffman 树的根"]
H --> I["释放堆结构,返回根节点"]
- 编码
flowchart TD
A["开始生成编码表"] --> B["从 Huffman 树根节点出发,路径字符串 sign = \"\""]
B --> C{"当前节点是否为空?"}
C -->|"是"| D["直接返回"]
C -->|"否"| E{"当前节点是否为叶子?"}
E -->|"是"| F["如果路径长度为 0(仅一个符号),则赋码“0”;否则将当前路径字符串保存到对应字符的编码表"]
F --> G["返回上一层"]
E -->|"否"| H{"是否有左子树?"}
H -->|"是"| I["在路径尾追加 '0',递归访问左子树"]
I --> J["返回时恢复路径字符串长度"]
H -->|"否"| J
J --> K{"是否有右子树?"}
K -->|"是"| L["在路径尾追加 '1',递归访问右子树"]
L --> M["返回时恢复路径字符串长度"]
K -->|"否"| N["返回上一层"]
- 压缩
flowchart TD
A["开始压缩"] --> B["打开原始文件,若失败则报错并退出"]
B --> C["读取文件,统计每个字节的出现频次到 cnt[]"]
C --> D["回到文件开头,构造 Info 数组(包含字符和频次)"]
D --> E["调用 buildHuffmanTree 构建 Huffman 树"]
E --> F["初始化编码表,将表置空"]
F --> G["递归生成每个字符的比特串编码到编码表 table"]
G --> H["计算所有字符编码后的总比特数 total_bits"]
H --> I["根据 total_bits 计算末尾补零的位数 padding"]
I --> J["打开输出文件,若失败则报错并退出"]
J --> K["先写入 256 个频次值(long long 数组)"]
K --> L["再写入 1 字节的 padding 信息"]
L --> M["初始化 BitWriter 以便按位写入"]
M --> N["回到原始文件开头"]
N --> O{"读取一个字节 ch?"}
O -->|"是"| P["查表得到 ch 的比特串,按比特写入 BitWriter"]
P --> O
O -->|"否"| Q["flush BitWriter,将剩余位填充后写出"]
Q --> R["关闭输入/输出文件"]
R --> S["释放 Huffman 树等资源"]
S --> T["打印“压缩完成”信息并返回"]
- 解压
flowchart TD
A["开始解压"] --> B["打开压缩文件,若失败则报错并退出"]
B --> C["依次读取 256 个频次值到 cnt[]"]
C --> D["读取 1 字节 padding"]
D --> E["计算原始文件的总字节数 sum_cnt = Σ cnt[i]"]
E --> F["构造 Info 数组,包含出现过的字符及其频次"]
F --> G["调用 buildHuffmanTree 重建 Huffman 树"]
G --> H["打开输出文件,若失败则报错并退出"]
H --> I["初始化 BitReader 以便按比特读取"]
I --> J["设置写出计数 written = 0,从树根 node = root"]
J --> K{"written < sum_cnt?"}
K -->|"否"| L["关闭文件,释放资源,打印“解压完成”并返回"]
K -->|"是"| M["从 BitReader 中读取一个比特 bit"]
M --> N{"bit 是否为 -1 (结束)?"}
N -->|"是"| O["报错“比特流意外结束”,退出循环"]
N -->|"否"| P["如果 bit=0,则 node=node->左子树;否则 node=node->右子树"]
P --> Q{"node 是否到达叶子?"}
Q -->|"否"| K
Q -->|"是"| R["输出 node 对应的字符到文件;written++; 回到树根 node=root"]
R --> K
函数调用关系图:
flowchart LR
main --> print_usage
main --> compress_file
main --> decompress_file
compress_file --> buildHuffmanTree
compress_file --> encode
compress_file --> bw_init
compress_file --> bw_write_code
compress_file --> bw_flush
compress_file --> freeHuffmanTree
decompress_file --> buildHuffmanTree
decompress_file --> br_init
decompress_file --> br_read_bit
decompress_file --> freeHuffmanTree
buildHuffmanTree --> init
buildHuffmanTree --> push
buildHuffmanTree --> pop
push --> _up
pop --> _down
调用关系说明:
- 主程序
main - 根据第一个参数是
-c(压缩)还是-d(解压)来分支:-c→ 调用compress_file(infile, outfile)-d→ 调用decompress_file(infile, outfile)
- 压缩流程(
compress_file) - 先用
fopen/fread统计频次到cnt[] - 将非零频次封装为
Info signs[],调用buildHuffmanTree构造 Huffman 树 - 调用
encode生成table[ch](按sign[]递归下去产生比特串) - 计算
total_bits与padding - 打开输出文件,写入 256×
cnt[i]+ 1×padding - 用
BitWriter(bw_init、bw_write_code、bw_flush)按位写真正的 Huffman 比特流 - 释放树与中间数组
- 解压流程(
decompress_file) - 先用
fopen/fread读回 256 个cnt[i]+ 1 个padding - 计算
sum_cnt = ∑ cnt[i] - 将非零频次封装为
Info signs[],调用buildHuffmanTree重建 Huffman 树 - 打开输出文件,初始化
BitReader(br_init) - 循环
br_read_bit,沿树从根到叶子遍历,遇到叶子则fputc输出一个字节,直到写满sum_cnt个字节 - 释放树与中间数组
4. 调试分析
问题与解决:
- 对于C语言文件输入输出不太掌握,通过大模型了解了相关的语句和用法。
- 对于二叉堆的实现不太了解,在OI-wiki上找到了相关资料。
- 一开始没有考虑到字符信息,只统计了频次,发现这样在后续编码会很麻烦,设计了结构体将二者绑定。
- 对于只有单个字符不断重复的文件,遍历Huffman树时会出现问题,通过特殊判断解决。
改进方向:
- 判断文件类型,如果是已经压缩过的文件,不再进行压缩。
- 判断文件大小,如果文件很小,写入频次表占用的空间开销更大,则不进行压缩。
5. 用户使用说明
运行环境:GCC 13.2.0
用法:
压缩:程序路径 -c 原始文件路径 压缩后文件路径
解压:程序路径 -d 压缩文件路径 解压后文件路径
输入示例:
PS D:\wyk\Study\DataStructure> .\compress.exe -c .\kmp.c .\kmp.huf
输出示例:
压缩完成:".\kmp.c" → ".\kmp.huf"
原始字节总数 = 496,压缩后比特流总位数 = 2153,padding = 7
,压缩后字节总数 = 270
6. 测试结果
测试1
输入1:
PS D:\wyk\Study\DataStructure> .\compress.exe -c .\kmp.c .\kmp.huf
输出1:
压缩完成:".\kmp.c" → ".\kmp.huf"
原始字节总数 = 496,压缩后比特流总位数 = 2153,padding = 7
,压缩后字节总数 = 270
输入2:
PS D:\wyk\Study\DataStructure> .\compress.exe -d .\kmp.huf .\kmp.cpp
输出2:
解压完成:".\kmp.huf" → ".\kmp.cpp"
共还原原始字节数 = 496
比较解压后的文件和原文件内容
kmp.c
#include <stdio.h>
void get_nextval(char T[], int nextval[]) {
int i = 1, j = 0;
nextval[1] = 0;
while (i < T[0]) {
if (j == 0 || T[i] == T[j]) {
++i, ++j;
if (T[i] != T[j]) nextval[i] = j;
else nextval[i] = nextval[j];
} else {
j = nextval[j];
}
}
}
int main() {
char t[7] = {7, 'a', 'a', 'a', 'a', 'b', '\0'};
int nextval[10] = {0};
get_nextval(t, nextval);
return 0;
}
kmp.cpp
#include <stdio.h>
void get_nextval(char T[], int nextval[]) {
int i = 1, j = 0;
nextval[1] = 0;
while (i < T[0]) {
if (j == 0 || T[i] == T[j]) {
++i, ++j;
if (T[i] != T[j]) nextval[i] = j;
else nextval[i] = nextval[j];
} else {
j = nextval[j];
}
}
}
int main() {
char t[7] = {7, 'a', 'a', 'a', 'a', 'b', '\0'};
int nextval[10] = {0};
get_nextval(t, nextval);
return 0;
}
内容完全一致。
对比压缩后的文件大小
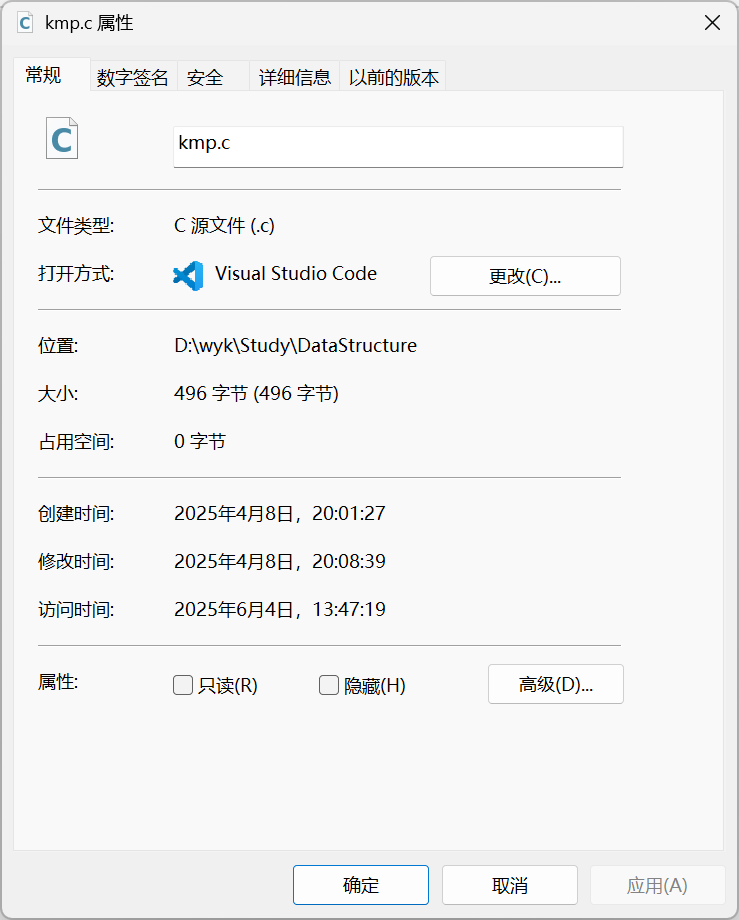
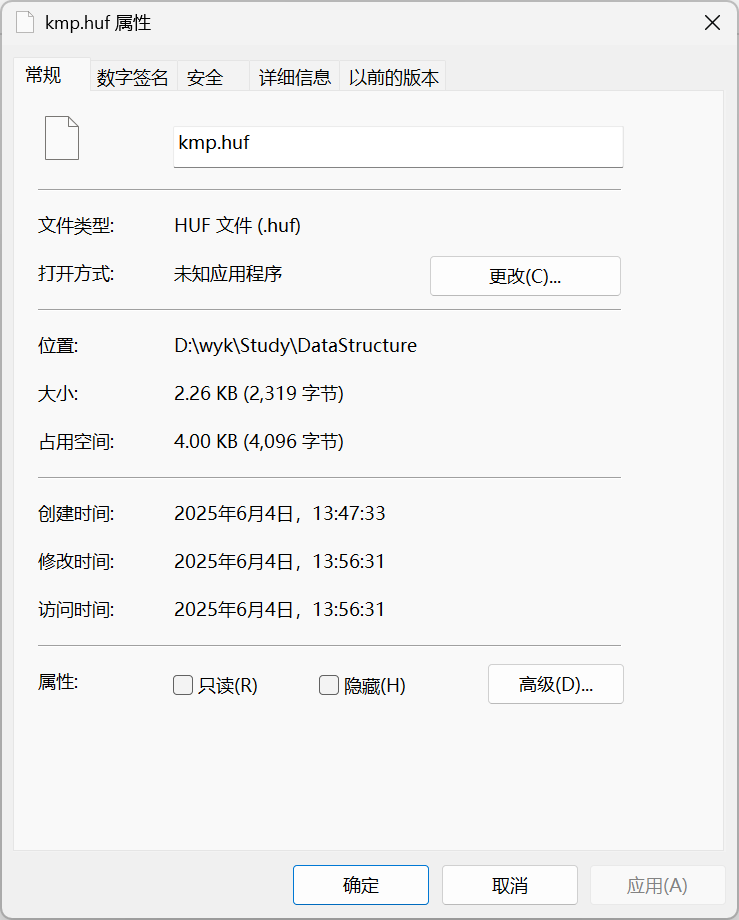
发现压缩后文件反而变大,这是由于kmp.c太小,写入频率表占用的空间反而更大。
测试2
生成1GB全0二进制文件
PS D:\wyk\Study\DataStructure> fsutil file createnew .\big.bin 1073741824
已创建文件 D:\wyk\Study\DataStructure\big.bin
压缩
PS D:\wyk\Study\DataStructure> .\compress.exe -c .\big.bin .\big.huf
压缩完成:".\big.bin" → ".\big.huf"
原始字节总数 = 1073741824,压缩后比特流总位数 = 1073741824,padding = 0
,压缩后字节总数 = 134217728
解压
PS D:\wyk\Study\DataStructure> .\compress.exe -d .\big.huf .\big2.bin
解压完成(单符号优化):".\big.huf" → ".\big2.bin",写入 1073741824 字节
对比big.bin与big.huf的大小:
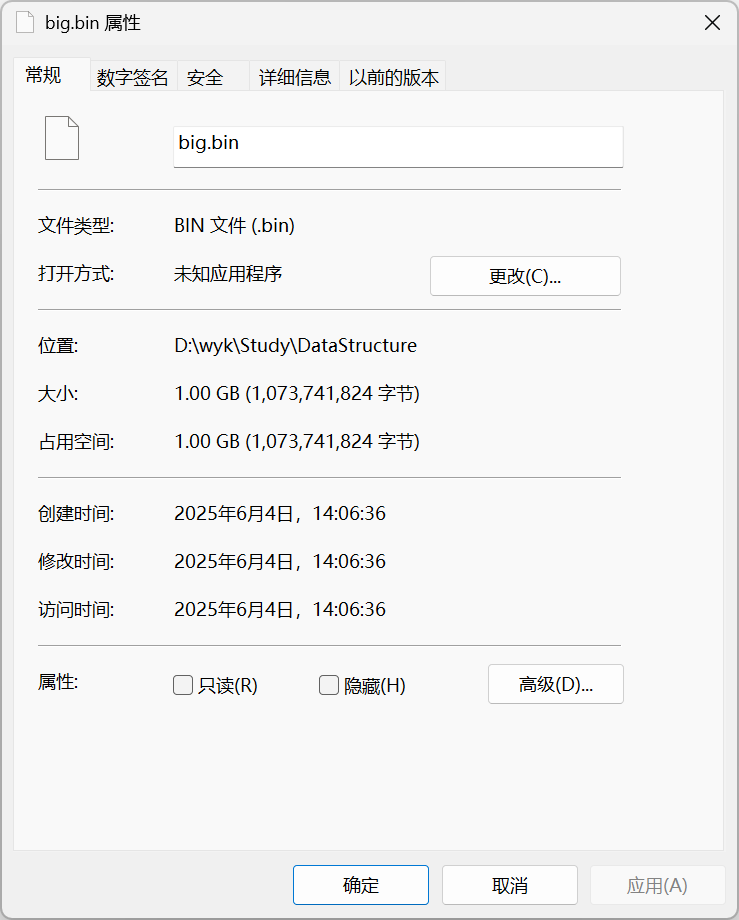
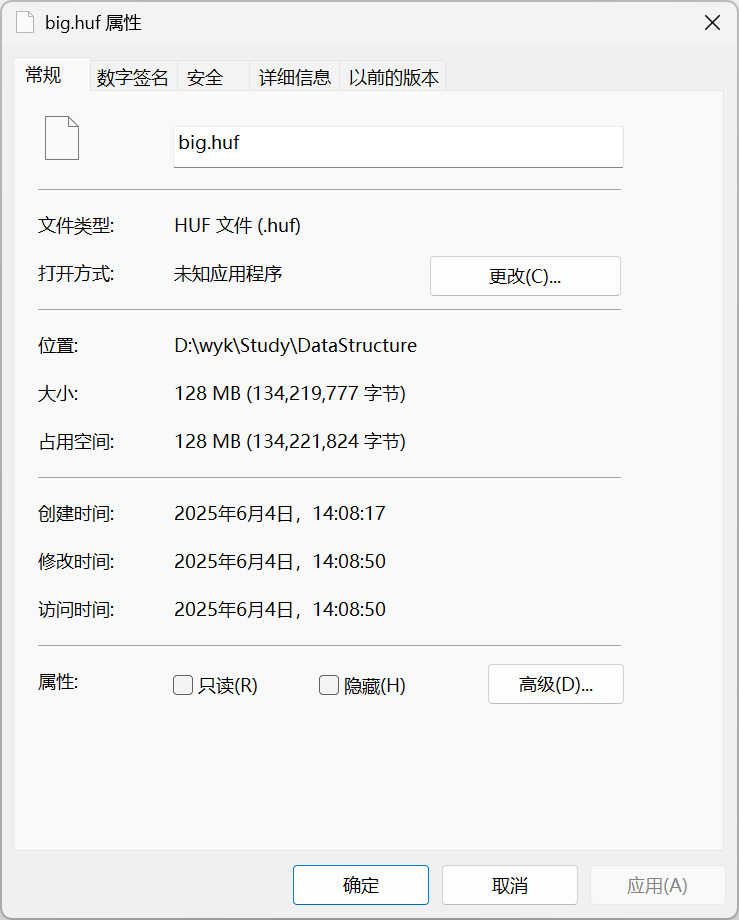
1GB的文件被压缩到了128MB,可以看到,对于字符频率差异显著的文件,压缩率很高。